歡迎回到我們的30天人臉技術探索之旅!我們已經理解了人臉偵測以及人臉關鍵點偵測等人臉在2D平面上的資訊了 今天我們將介紹人臉3D資訊--頭部姿勢估計技術(Head pose),這是電腦視覺領域中一個引人注目的研究方向。我們將探討頭部姿勢估計的定義、應用、傳統方法以及深度學習在這一領域的優越性。
在探討後續的任何更加深入的議題之前,我們應該先介紹一下什麼是頭部姿勢估計!
頭部姿勢估計是指從圖像或視頻中推斷出人物頭部的方向和角度。這包括頭部的旋轉(Roll)、俯仰(Pitch)和橫擺(Yaw)等方向。如下圖(圖片ref):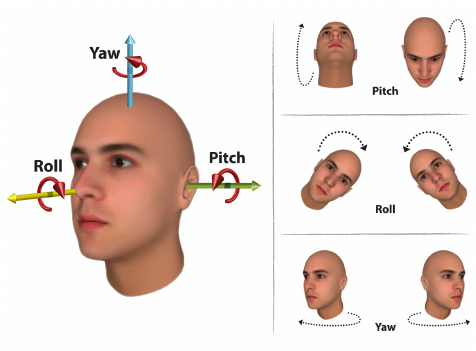
頭部姿勢的準確估計對於許多應用至關重要,如人機交互、虛擬現實、自動駕駛系統等。以下也是一些常見的應用場景:
1. 虛擬現實(VR)
在虛擬現實環境中,頭部姿勢估計是提供沉浸式體驗的關鍵因素。通過追蹤使用者頭部的運動,系統可以調整虛擬場景,使之更符合使用者的視覺感知。
2. 人機交互
頭部姿勢估計可用於改進人機交互的方式。例如,在電腦遊戲中,頭部的轉動可以直接映射到遊戲角色的視角變化,提供更自然的操作體驗。
3. 監控和安全
在監控系統中,頭部姿勢估計可用於檢測人物的注意力方向。這在安全系統中特別有用,例如監控駕駛員的注意力是否集中在駕駛上。舉例來說,在駕駛狀態監控的任務上,如果我們要判斷駕駛是否在轉彎時有轉頭看向後照鏡,那此時Head pose 的預測功能就可以派上用場!
在深度學習方法興起之前,人們通常使用傳統的計算機視覺技術來估計頭部姿勢。這些方法通常基於特徵點的追蹤,如眼睛、鼻子和嘴巴。一個蠻普及的過程大致如下:
1.事先定義好人臉的 3D 模型,並找到這個模型上的關鍵點座標,如下圖左邊
2.找到受試照片的關鍵座標(2D),如下圖右邊
3.通過 cv2.solvePnP 找尋出一個轉換矩陣可以將 3D 的關鍵點座標投影成受試照片的關鍵座標(2D),而其中這個轉換中的旋轉矩陣即為 Head pose!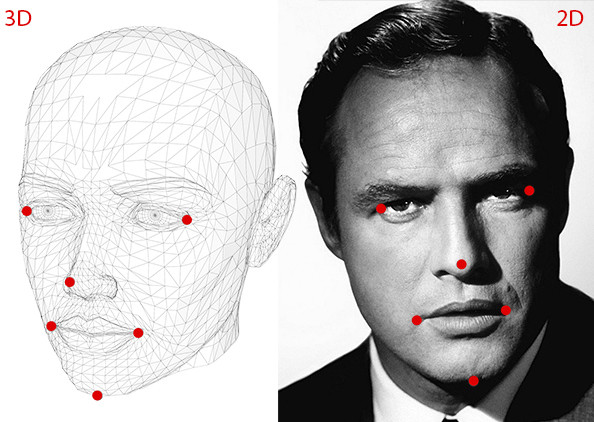
以上這個步驟的優點十分明顯就是簡單且方便!透過傳統的數學計算即可以找到 Headpose
但比較顯而易見的問題也隨之而來:
1.如果人臉關鍵點足夠準確,則 Headpose 的準確度會受到大幅影響
2.每個人的3D人頭不相同,如果都使用同一個 3D 模型則一定是不準確的,但如果每個人要有自己的模型確實功夫也是不少
我們這裡提供一個簡單基於 Dlib & OpenCV 的例子如下,有興趣的人可以準備一張照片試試看!
Step.1 安裝 Lib
pip install dlib opencv-python
Step.2 完整的程式(附上註解)
import dlib
import cv2
import numpy as np
# 初始化 Dlib 的人臉檢測器和姿勢估計器
detector = dlib.get_frontal_face_detector()
# 我們這裡使用 dlib 中預測 landmark 的
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") # 需要提供檢測器模型
# 定義用來參考的 6 點關鍵點的 3D 座標
def ref3DModel():
modelPoints = [[0.0, 0.0, 0.0], # Nose tip
[0.0, -330.0, -65.0], # Chin
[-225.0, 170.0, -135.0], # Left eye left corner
[225.0, 170.0, -135.0], # Right eye right corner
[-150.0, -150.0, -125.0], # Left Mouth corner
[150.0, -150.0, -125.0]] # Right mouth corner
return np.array(modelPoints, dtype=np.float64)
# 我們這裡是使用 Dlib自帶的 68 點 facial landmark 預測,但因為我們只有 6 點參考座標,所以我們只用這 6 點當參考
def ref2dImagePoints(shape):
imagePoints = [[shape.part(30).x, shape.part(30).y],
[shape.part(8).x, shape.part(8).y],
[shape.part(36).x, shape.part(36).y],
[shape.part(45).x, shape.part(45).y],
[shape.part(48).x, shape.part(48).y],
[shape.part(54).x, shape.part(54).y]]
return np.array(imagePoints, dtype=np.float64)
# 讀取測試照片
img_path = "path/to/your/test/image.jpg"
img = cv2.imread(img_path)
# 將照片轉換為灰度
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 進行人臉檢測
faces = detector(gray)
for face in faces:
# 進行面部特徵點檢測
landmarks68 = predictor(gray, face)
# 提取6個特徵點的座標
landmarks6 = ref2dImagePoints(landmarks68)
points = np.array([(landmarks6.part(i).x, landmarks6.part(i).y) for i in range(6)])
# 得到 3D 參考座標
ref_3d_point = ref3DModel()
# 相機內部參數
focal_length = frame.shape[1]
center = (frame.shape[1] / 2, frame.shape[0] / 2)
camera_matrix = np.array([[focal_length, 0, center[0]],
[0, focal_length, center[1]],
[0, 0, 1]], dtype="double")
# 畸變係數(在實際應用中,可能需要進行校正)
dist_coeffs = np.zeros((4, 1))
# 使用 solvePnP 函數估計姿勢
_, rotation_vec, translation_vec = cv2.solvePnP(
object_pts, image_pts, camera_matrix, dist_coeffs, flags=cv2.SOLVEPNP_ITERATIVE)
# 將旋轉向量轉換為旋轉矩陣
rotation_mat, _ = cv2.Rodrigues(rotation_vec)
# 計算歐拉角(pitch、yaw、roll)
pitch, yaw, roll = cv2.decomposeProjectionMatrix(rotation_mat)[:3]
# 將角度轉換為度數
pitch = pitch[0]
yaw = -yaw[0]
roll = roll[0]
# 在影像上繪製角度信息
cv2.putText(frame, f'Pitch: {pitch:.2f}', (20, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.putText(frame, f'Yaw: {yaw:.2f}', (20, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.putText(frame, f'Roll: {roll:.2f}', (20, 150), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 顯示結果影像
cv2.imshow("Head Pose Estimation", img)
cv2.waitKey(0)
# 釋放資源
cv2.destroyAllWindows()
近年來,隨著深度學習的快速發展,特別是卷積神經網絡(CNN)的成功應用,深度學習在頭部姿勢估計方面取得了顯著的進展。以下是深度學習方法的一些優點:
1. 自動特徵學習
傳統方法需要手動設計特徵(Facial landmark)來表示頭部的位置和方向。而深度學習方法能夠自動學習最佳的特徵表示,減少了對特徵設計的依賴。
2. 更強大的建模能力
深度學習模型能夠處理更複雜的視覺模式,從而更準確地估計頭部的姿態。這包括處理不同照明條件、姿勢變化和多人場景等情況。舉個例子來說,一張較為模糊的照片裡,我們不一定可以很精準的點出 Facial landmark,但以我們的受眼來看是不是要猜出他頭轉的方向其實還是可以大致猜得出來呢?
3. 端對端學習
深度學習模型可以通過端對端的方式學習,直接從原始數據中學到映射關係,而不需要手動的中間步驟。這一個最大好處讓我們可以藉由大量數據讓模型自行學會預測角度(data-driven)而無需有人類的提示!
深度學習的方法其實最簡單的大家可以想成就是透過一個 CNN 區壓成 Feature,然後透過一層 Fully connecte layer 去回歸出 Roll, Pitch, 以及 Yaw。我們在這個Head pose這個主題中會著重在深度學習的方法上,會交大家如何建構出自己的人臉模型!
近年來,研究人員提出了許多基於深度學習的頭部姿勢估計方法。其中,一些方法融合了多模態信息,如RGB圖像、深度圖像和熱度圖,以提高估計的準確性。此外,遷移學習、強化學習等技術也在頭部姿勢估計中得到了應用。
頭部姿勢估計技術是人臉技術領域中一個重要而引人注目的方向。傳統方法為這一領域的研究奠定了基礎,而深度學習的引入使得頭部姿勢估計取得了更大的突破。隨著技術的不斷發展,我們有理由相信,在未來頭部姿勢估計技術將在更多應用場景中發揮重要作用。明天我們將帶著大家實現自己的 Headpose model!
1.Bulat, A., & Tzimiropoulos, G. (2017). How far are we from solving the 2D & 3D face alignment problem? (and a dataset of 230,000 3D facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision.
2.Asthana, A., Zafeiriou, S., Cheng, S., & Pantic, M. (2014). Incremental face alignment in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
3.Zhou, X., Fan, J., Cao, Z., Jiang, Y., & Yin, Q. (2013). Extensive facial landmark localization with coarse-to-fine convolutional network cascade. In Proceedings of the IEEE International Conference on Computer Vision.
4.Lokku, Guru Kumar, G. Harinatha Reddy, and M. N. Giri Prasad. "Automatic face recognition for various expressions and facial details." International Journal of Innovative Technology and Exploring Engineering (IJITEE) 8.9S3 (2019): 264-268.


 iThome鐵人賽
iThome鐵人賽